�����͡��ʥǡ����١������������
��-�����Х�������ե��ޥƥ������ȥǡ����١���
�� ���̤��������
��ݥҥȥ��Υ�ץ���������
�ʤɤΤ褦�������Υ�α������������Ū�˷��ꤷ�褦�Ȥ������Ȥ��͡�����ʪ��ǹԤ��Ƥ����ꡢ
�������������ɸ�˥���ѥ�����Ω�ι�¤������Ū�����餫�ˤ��褦�Ȥ���ʸ���ʳؾʤ�
����ѥ����������ץ��������Ȥ����ä��ꡢ
��˦���ȯ�����Ƥ��륿��ѥ������̤���ߺ��Ѥʤɤ�����Ū��Ĵ�٤�ץ��ƥ�������Ϥʤɡ�
��̿�ξ��������Ū��Ĵ�٤�Ȥ������Ȥ�����ˤʤäƤ��ޤ���
���η�̡�������θ���Ԥ���ͭ�Ѥ����̤Υǡ�����ȯ������Τǡ� ������ͭ���˳��ѤǤ���褦���͡��ʵ��ء���Ū�ǥǡ����١���������Ƥ��ޤ���
���η�̡�������θ���Ԥ���ͭ�Ѥ����̤Υǡ�����ȯ������Τǡ� ������ͭ���˳��ѤǤ���褦���͡��ʵ��ء���Ū�ǥǡ����١���������Ƥ��ޤ���
���ǡ����١���
�ǡ����١����Ȥϡ����̤Υǡ����ν��ޤ�Τ��ȤǤ���
�ǡ����١����Ϥ���ñ�ΤǤ����Ѥ���Τ����ѤǤ���
���Τ���ǡ����١����ˤϡ�
��Ū�Υǡ����˥����������뤿��Υ�����ɸ����ʤɤΤǤ��륤���ե�������¸�ߤ��ޤ���
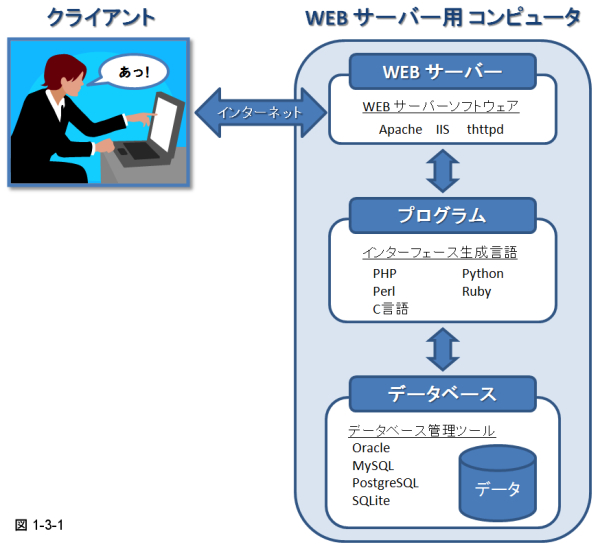
�Х�������ե��ޥƥ������ˤ�����ʿ��Υǡ����١�����¸�ߤ��ޤ���
�����Υǡ����١����ϡ��礭�����Ĥ�ʬ�ह�뤳�Ȥ��Ǥ��ޤ���
- ¬���̤��Τ�ΤΥǡ����١���
��DNA�����ߥλ�������ѥ���Ω�ι�¤�κ�ɸ�ǡ������� - ¬���̤����������������������ǡ����١���
������ѥ����Υ��ߥλ������Ω�ι�¤�����������ʬ�ष���ǡ����١������� - �嵭���Ĥ��Ȥ߹�碌���ǡ����١���
����̿�����Ϣ�μ�ʥǡ����١���
- ��������ǡ����١���
��������ǡ����١����ϡ�DNA��RNA�α�������Ȥ���������ʸ������ʤɤܤ����ǡ����١����Ǥ���
���Σ��Ĥϡ�̩�ܤ�Ϣ�ȤΤ�ȡ�DDBJ/EMBL/GenBank ��ݱ�������ǡ����١�����
���ۤ��Ƥ��룳���� DNA �ǡ����ХǤ��ꡢ���ߤ��Υǡ����˺����ʤ��褦�ˡ�
���Ū�˾������Ȥꤷ�Ƥ��ޤ���
- NCBI/GenBank
�ƹ� NCBI(National Center for Biotechnology Information)�����ġ� - EMBL/EBI
���� EMBL(European Molecular Biology Laboratory)��EBI(European Bioinformatics Institute)�����ġ� - DDBJ
���ܤι�Ω�����ظ���� ��̿����DDBJ ���楻����DNA Data Bank of Japan�ˤ����ġ�
[ �齬 1-1 ]
AB028630 �Ȥ�������ȥ ID ����Ͽ����Ƥ��� Clostridium perfringens (�����륷���) ͳ��α�������ĤΥ����Ȥ��줾��Ǹ��������ޤޤ������������ɤΤ褦�˰ۤʤ뤫Ĵ�٤Ƥߤ褦��
�� AB028630�����ǰ�����ȯ��Ĵ����� VirR/VirS �ˤ�����椵��Ƥ��������
AB028630 �Ȥ�������ȥ ID ����Ͽ����Ƥ��� Clostridium perfringens (�����륷���) ͳ��α�������ĤΥ����Ȥ��줾��Ǹ��������ޤޤ������������ɤΤ褦�˰ۤʤ뤫Ĵ�٤Ƥߤ褦��
�� AB028630�����ǰ�����ȯ��Ĵ����� VirR/VirS �ˤ�����椵��Ƥ��������
- ���ߥλ�����ǡ����١���
���ߥλ�����ǡ����١����ϡ����ߥλ�������Ȥ���������ʸ������ʤɤܤ����ǡ����١����Ǥ���
- UniProt
������ SIB��Swiss Institute of Bioinfomatics�ˤȡ�EBI��European Bioinfomatics Institute�� ����Ʊ�ǹ��ۤ������ߥλ�����ǡ����١����Ǥ��� ����ѥ����ε�ǽ����ʤɤ�ޤޤ�Ƥ��ޤ��� - PIR
�ƹ硼����������ؤˤ�깽�ۤ��줿���ߥλ�����ǡ����١����Ǥ��� �ե��ߥ�������ѡ��ե��ߥ��ʬ��Ȥ�������ħ�Ť���ɥᥤ������ޤ�Ǥ��ޤ���
[ �齬 1-2 ]
�齬 1-1 ������줿�����Ҥ˥����ɤ���Ƥ��륿��ѥ����ε�ǽ��ե��ߥ�ˤĤ��ơ� Swiss-Prot��PIR ��protein_id �Ǹ����ˤ��줾���Ĵ�٤Ƥߤ褦��
�ޤ�������ѥ���̾�Ǥ⸡�����Ƥߤ褦��
�齬 1-1 ������줿�����Ҥ˥����ɤ���Ƥ��륿��ѥ����ε�ǽ��ե��ߥ�ˤĤ��ơ� Swiss-Prot��PIR ��protein_id �Ǹ����ˤ��줾���Ĵ�٤Ƥߤ褦��
�ޤ�������ѥ���̾�Ǥ⸡�����Ƥߤ褦��
- ����ѥ���Ω�ι�¤�ǡ����١���
����ѥ���Ω�ι�¤�ǡ����١����ˤϡ��礭��ʬ����2���ढ��ޤ���
���Ĥϡ�����ѥ����˴ޤޤ�븶�Ҥ�3������ɸ�ǡ����Υǡ����١����Ǥ���PDB��Protein Data Bank�ˤǡ�
�⤦���Ĥϡ���¤��ʬ�ࡢ��Ӥ����ǡ����١����Ǥ���SCOP��CATH�ʤɤǤ���
- PDB
RCSB��Research Collaboratory for Structural Bioinfomatics�� �ˤ�깽�ۤ��줿�� ����ѥ�����3����Ω�ι�¤�ǡ����١����Ǥ��� �Ƹ��Ҥ�3������ɸ�ǡ�������ӹ�¤��Ǯ��ư�����٤�ɽ�����ٰ��ҤΥǡ�����ʸ������ʤɤ����ܤ���Ƥ��ꡢ ����ѥ����˸¤餺���˻��Υǡ�����ޤޤ�Ƥ��ޤ���
- ����ѥ���Ω�ι�¤ʬ��ǡ����١���
����ѥ������Τ�Ρ��Ĥޤꥢ�ߥλ�����ϡ����Τ���10������ʾ夢��Ȥ�����Ƥ��ޤ�����
����ѥ��������������Ω�ι�¤�ϡ������������٤����ʤ��ȹͤ����Ƥ��ޤ���
����Ω�ι�¤�����ܤ���ʬ�ࡢ��Ӥ�ԤäƤ���ǡ����١����� SCOP �� CATH �Ǥ���
���Τ褦�ʹ�¤ʬ��ϡ�����ѥ����ε�ǽ��ͽ¬�����Ϥ���Τ����˽��פǤ���
- SCOP
�ѹ� MRC Laboratory of Molecular Biology �ˤ�깽�ۤ��줿�ǡ����١����ǡ� SCOP �ϡ�Structural Classification of Proteins ��ά�Ǥ���
����ѥ�����Ω�ι�¤���ܤ���Ӥ�����ư��ʬ�ष�Ƥ��ޤ�������3�Ĥγ��ؤˤ��ʬ�व��Ƥ��ޤ���- Class�������¤�Υ����פˤ�� All ����All �¡���/�¡���+�¡��ޥ���ɥᥤ��ѥ������쥿��ѥ����������ʥ���ѥ�����������ɥ����롢������١��ڥץ��ɡ��ǥ����줿����ѥ�����ʬ��
- Fold��Ω�ι�¤�Τߤ����
- Superfamily�����ߥλ��������Ʊ�����㤤����Ω�ι�¤����ӵ�ǽ�����
- Families�����ߥλ��������Ʊ�����⤤���롼��
- CATH Protein Structure Classification
University College London �ˤ�깽�ۤ��줿�ǡ����١����Ǥ��� ����ѥ�����Ω�ι�¤��ץ������ˤ��ɥᥤ��ñ�̤�ʬ�䤷�� ʬ�䤵�줿�ɥᥤ��¤��ץ�����प��ӿͤ��ܤ�ʬ�ष�ޤ��� ���ˡ�5�Ĥγ��ؤˤ��ʬ�व��Ƥ��ޤ���- Class (C)����¤�Υ����פˤ�� Mainly Alpha��Mainly Beta��Mixed Alpha-Beta��Few Secondary Structures ��4�����ʬ��
- Architecture (A)����¤������Ū�����֤�������Ƥ�����
- Topology (T)����¤������Ū�����֤ȤĤʤ�������������Ƥ�����
- Homologous Superfamily (H)�����̤οʲ�Ū�������äƤ����ͽ�ۤ������
- OLIGAMI
�����å�����ӽ������줿��ʪ��Ū������¤�ǡ�����SCOP�γ��ؤǡ����뤳�Ȥ��Ǥ��롣
ƣ�����漼�����ġ�
- �����ǡ����١���
����ѥ����ϡ��͡��ʽ���������ޤ�����������Ǥ�ʣ���ʤΤ������Ǥ����͡�������ʬ�����ʤ���Ϣ�뤵��Ƥ����ޤ���
���μ��ࡢʬ���λ����ʤɤˤ�äơ�Ư�����Ѥ��ޤ������������¤Ӥ�Ư���Ȥδط����ˤĤ��ƤϤޤ����餫�ˤ���Ƥ��ޤ���
�����ǡ������Ĥ��θ��浡�ؤˤ�äơ������˴ؤ���ǡ����١��������ۤ��졢��������Ƥ��ޤ���
- ���������ʳ�����ǡ����١���
���ȵ������縦��� �����幩�ظ��楻�������ġ� - RINGS (Resource For INformatics Of Glycomes at Soka)
�ϲ�����ڲ����漼�����ġ�
- ����ǡ����١���
�饤�ե������ˤ������͡��ʾ�������礷���ǡ����١����Ǥ���